Where’s My p-Value? Rethinking Evidence in the Age of GenAI

Bernhard Obenhuber
Aug 16, 2025

As economists and sovereign risk analysts, we are deeply familiar with statistics and econometrics. When someone makes an economic claim, our instinct is to demand evidence — to move away from anecdote, towards correlation, and as close as possible to causality. That requires statistical rigor from start to finish: selecting dependent and independent variables, choosing an appropriate model, ensuring time-series coverage without selection bias, checking for cross-correlations, and avoiding in-sample overfitting.
I am a long-time admirer of Marcos López de Prado’s work on the fallacies of backtest overfitting — a topic too often ignored. You can find his seminal work here (Link).
At CountryRisk.io, we are deliberately cautious when making claims about our models’ predictive power, whether in explaining or forecasting sovereign defaults or currency crises. This is informed by decades of experience with the limitations of macroeconomic data and the many pitfalls in model design. That said, we remain strong advocates for data-driven, quantitative approaches to country and sovereign risk analysis.
GenAI: The Other Side of the Coin
When approximating sovereign default risk, we examine a broad set of indicators and apply various quantitative models. Yet, some dimensions of sovereign risk are inherently qualitative. One could argue — citing Lord Kelvin’s famous dictum, “If you cannot measure it, you cannot improve it” — that everything can be quantified. I am happy to debate the limits of that view over a drink.
For the sake of argument, let’s equate qualitative analysis with text-based assessments, and quantitative analysis with numeric statistics. On that basis, generative AI is particularly well suited to qualitative tasks — for example:
- Retrieving relevant passages from large volumes of country reports using semantic search.
- Summarising findings from multiple sources.
- Extracting sentiment on a given policy, sector, or macroeconomic trend.
But this raises the question: how do we measure the quality and accuracy of GenAI outputs? And how can we run regular “performance reviews” of our AI agents?
At CountryRisk.io, we work with more than a dozen AI tools, each with distinct capabilities, and integrate them into workflows spanning research through report production. Early in our GenAI adoption, we began collecting ideas — and datasets — for systematically evaluating and benchmarking LLM performance.
The motivation is the same as with any quantitative model: choosing the right model for the task, balancing quality against cost. For traditional econometric models, computational cost was negligible; with LLMs applied to large datasets, the monetary cost — and its environmental footprint — is real.
Given the pace of LLM development, we also need robust, repeatable tests to understand how a new model performs relative to its predecessor. This helps predict how user outputs might change if we switch models.
Evaluation datasets
In this post, we focus on evaluating LLMs in the context of economic and country risk analysis. In a future post, we will address evaluation in tool-calling and agent orchestration. Here, we show two evaluation tasks.
Our first task is sentiment classification — labelling macroeconomic statements as strength, neutral, or weakness in the context of sovereign credit risk. For example:
- “Norway has a very low government debt-to-GDP ratio.” → Strength
- “The USA has been running large twin deficits for many years.” → Weakness
We previously wrote about the challenges of sentiment classification (Link). Since then, out-of-the-box LLMs have improved considerably. We maintain an expert-labelled dataset of ~3,000 macroeconomic statements, and task the LLM with assigning labels. This enables a direct LLM vs. human comparison.
We are not claiming academic rigor — ideally, multiple human experts would label each statement, with a consensus process for disagreements. That’s a future improvement. Below is a table showing accuracy across models for the 3,000 statements, followed by illustrative “error” cases:


In some cases, disagreements reflect genuine ambiguity rather than LLM error — different human experts might classify them differently.
Secondly, we turn to a more qualitative, or “artistic,” evaluation exercise: assessing how effectively an LLM can provide macroeconomic policy recommendations in response to a given economic scenario. Consider the following example:
“Bank balance sheets are weak and suffer from low profitability; NPLs are high and growing. While provisioning standards are adequate, classification remains lax, potentially masking solvency problems in at least some banks.”
Our objective is to determine whether the LLM can generate a sound and actionable recommendation in such a context. To do so, we need a reliable baseline for comparison. Creating thousands of bespoke risk and policy recommendation pairs in-house is beyond our resources. Instead, we turned to a ready-made source: IMF Article IV reports, which include a Risk Assessment Matrix section. This section presents risk scenarios alongside corresponding policy recommendations. An example from the latest Article IV report on Kosovo is provided below.
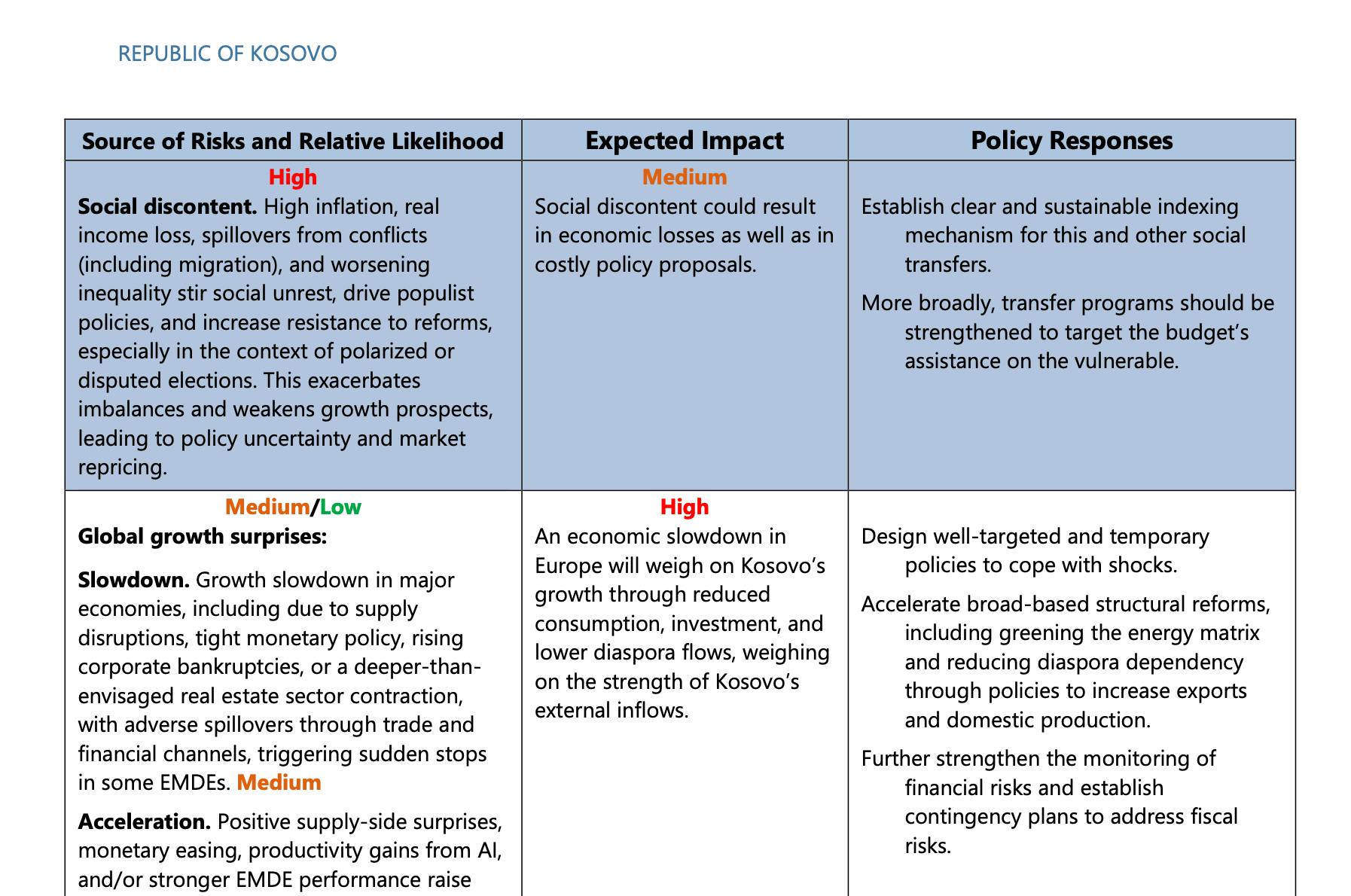
We first prompted the LLM to produce a concise policy recommendation based on the risk statement above. GPT-5 generated the following response:
“Conduct independent asset quality reviews and stress tests; tighten loan classification and provisioning, enforce timely write-offs. Accelerate NPL resolution through stronger insolvency and collateral enforcement and a centralized AMC or NPL trading platform. Require undercapitalized banks to raise capital or restructure; restrict dividends and use resolution tools, including mergers or exit. Intensify risk-based supervision and transparency with early intervention triggers and enhanced public disclosures.”
By contrast, the IMF’s policy response in the report was:
“Strengthen supervision and tighten prudential regulations. Take early action as signs of deteriorating asset quality emerge.”
To evaluate how closely the LLM’s recommendation aligns with the IMF’s, we need a quantitative measure of semantic similarity. For this, we use the Ragas Semantic Similarity Score—a metric that quantifies the degree of semantic alignment between a generated answer and a reference (ground truth). The score ranges from 0 to 1, with higher values indicating stronger semantic overlap.
How It Works
The process broadly involves:
- Embedding both texts (generated answer and reference) into high-dimensional vectors using a bi-encoder model.
- Computing the cosine similarity between these vectors.
- Returning the resulting similarity score (e.g., 0.8151).
In our example above, the returned similarity score was 0.8. In the table below, you find additional statements and the similarity score. So, what can go wrong with this approach. Actually, there are quite some drawbacks that one needs to be aware of:
- Surface-level agreement can mask factual errors – similar wording may hide wrong information.
- Insensitive to hallucinations – extra but incorrect details may not be penalized enough.
- Dependent on embedding model quality – poor or mismatched embeddings can give misleading scores.
- No error-type granularity – doesn’t tell you what is wrong (missing details, factual errors, irrelevance).
- Domain & language sensitivity – jargon or multilingual content can lower scores despite correct meaning.
Despite these potential limitations, we consider this a valuable component of a broader GenAI evaluation framework. In particular, it is useful for detecting issues when transitioning from one LLM to another. By automatically running the evaluation on the new model and comparing the results with those of the previous one, we can identify significant divergences early. If substantial differences emerge, we can halt the model switch and code deployment before any negative impact reaches end users.
Still learning
We are still adapting to the GenAI landscape, with its opportunities and hidden risks. One clear takeaway: start building your evaluation framework early; you will learn a lot and it is difficult to catch up at a later stage.
At CountryRisk.io, we use Langfuse to run evaluations and manage benchmark datasets. In future posts, we will share more on our methods and findings.
We welcome feedback on best practices for evaluating GenAI outputs in economic research and country risk analysis. Contact us at [email protected].