Let the machines take over

Jenny Asuncion
Jan 09, 2023

In recent weeks, news and social media have been flooded by takes on the latest version of GPT-3, the OpenAI-trained language model. Most of those who have tried it have been quite impressed, with many asking whether such a tool could eventually replace developers, lawyers, and other types of knowledge worker.
Data and analytics are at the heart of what we do at CountryRisk.io, so we get excited about any new developments in the area. As such, we’ve been keeping our eye on artificial intelligence natural language processing and related fields for some time. Although we don’t think that any model will make sovereign and country risk analysts redundant anytime soon, these tools offer capabilities that could change how we work for the better by improving the quality and timeliness of analyses. However, if country risk analysts are to incorporate such tools into their work in ways that add real value, they will surely need new skillsets.
Sentiment analysis
In this blog post, we want to share some of our experiences in testing GPT-3 in the context of sovereign risk analysis, including what we’ve learned about the utility and limitations of such tools for analysts. Specifically, we’ll focus on using sentiment analysis to determine whether a sentence is positive, neutral, or negative. This can help us track the sentiment (or polarity) towards a certain topic or country based on what other people are saying about it, such as whether the International Monetary Fund (IMF) Article IV reports on a given country are becoming more positive or negative. Doing this at scale across many countries and various sources can support analysts with country monitoring and designing early warning systems. It can also help us understand the economic narrative of a specific country—including positive and negative risks—and how it’s changing over time.
For a seasoned analyst, it’s usually easy to decide whether a sentence expresses positive or negative risk. Here are six examples, along with how we would classify each sentence:
- Very low external debt. Positive
- The most immediate risk is a slowdown in the reform momentum. Negative
- External debt monitoring and management remain very weak. Negative
- Vulnerable to the structural slowdown of the Chinese economy and U.S.-China geopolitical tensions. Negative
- Mostly concessional external debt. Positive
- The State enjoys a net creditor position and has a well-endowed sovereign wealth fund thanks to hydrocarbon production. Positive
Would the algorithms agree? Let’s have a look.
VADER
To be able to determine the sentiment of any sentence, an algorithm first needs to be provided with some heuristics upon which to base its decisions or trained on a large number of examples that have already been classified by humans.
One tool that’s sometimes used for sentiment analysis is the excellently monikered VADER (Valence Aware Dictionary and sEntiment Reasoner), which applies a lexicon and rules for sentiment analysis. While the authors state that VADER is specifically tuned for social media posts, they also say that it works on other kinds of text.
We got VADER’s take on our six sentences[1]:
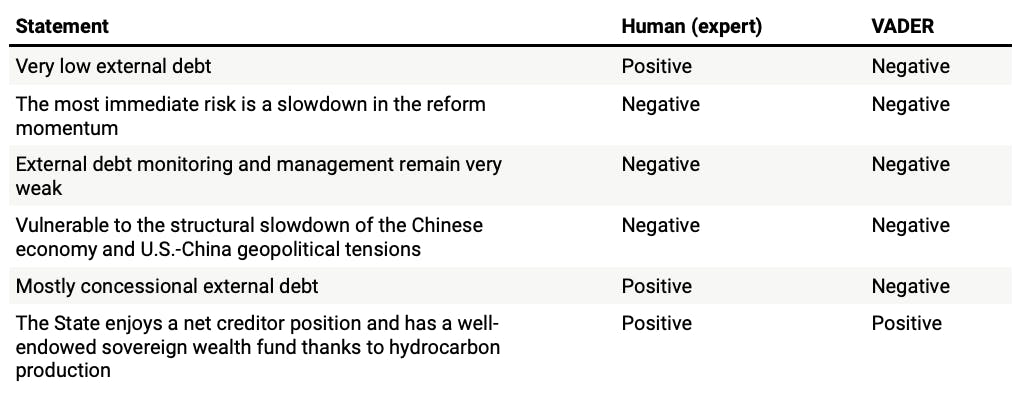
If we stipulate that the human is always correct, we can say that VADER scored a respectable four out of six. However, looking at just six hand-picked sentences is not very meaningful. So, we did the exercise for around 500 sentences got a success rate of 51%––better than the 33% success rate you’d get from random choice, but well short of a human analyst.
The reason for so many misses is the lexicon upon which the analysis is based, which is basically a list of words and their associated sentiment (e.g., fantastic = positive). Unfortunately, the creators of this lexicon clearly don’t think like country risk analysts. For instance, VADER always classes the words ‘risk’ and ‘debt’ as negative. This might be true in the context of a tweet saying “I have debt”; but in country risk, the word ‘debt’ lacks any sentiment unless it’s paired with a qualifier. These qualifiers might be simple, like ‘high debt’ (negative) or ‘low debt’ (positive). Or they may be more complicated. For instance, our fifth sentence—‘mostly concessional external debt’—is classed as positive by a human analyst because, unlike VADER, they understand that such debt is incurred at a relatively low cost compared to market-based financing.
To get more out of using VADER for sentiment analysis, then, we’d need to expand the underlying lexicon to account for how words are used in the context of country risk analysis.
Regression model
Next, we did something a little different. First, we used some natural language processing techniques to extract features from around 2,500 sentences, including the 500 we fed to VADER. This involved removing stop words and numbers from the sentences and tokenising them by breaking them down into single words and n-grams (e.g., ‘low debt’). Then, we used multinomial logistic regression to classify each sentence, which we also did manually. We used 80% of the sentences to estimate the regression (i.e., to train the model) and the rest to validate the model.
First, here are the results for our six sentences:
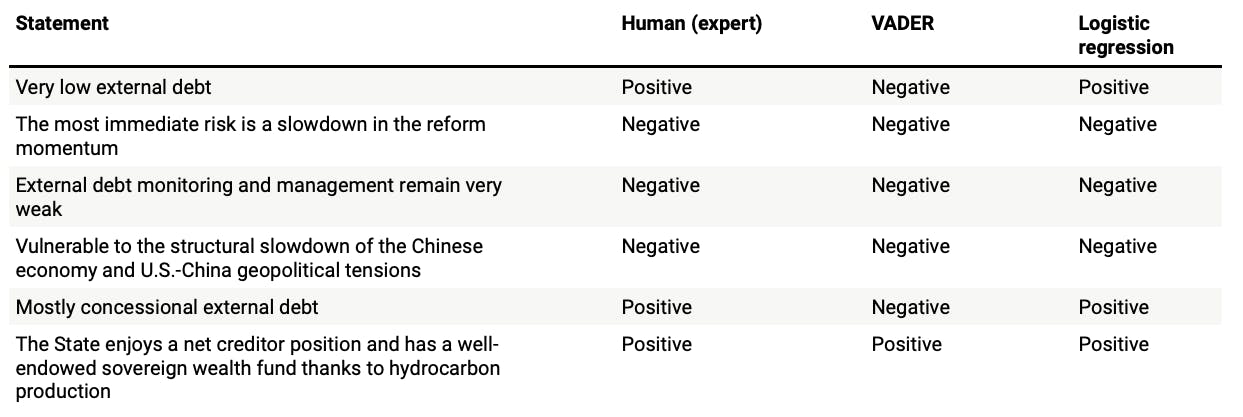
A perfect score! But not so fast… across all 500 sentences in our dataset, we got an accuracy score of 86%: not perfect, but a significant improvement on the 51% accuracy of the (out-of-the-box) VADER model. So, creating a training dataset clearly paid off, and it’s likely that an even larger dataset would improve the accuracy of logistic regression even further.
GPT-3
Or can we take a shortcut by applying the GPT3 model. We fine-tuned a model using again 2,000 training sentences set up as a completion task and validated it with the remaining 500. You can find the technical details here.
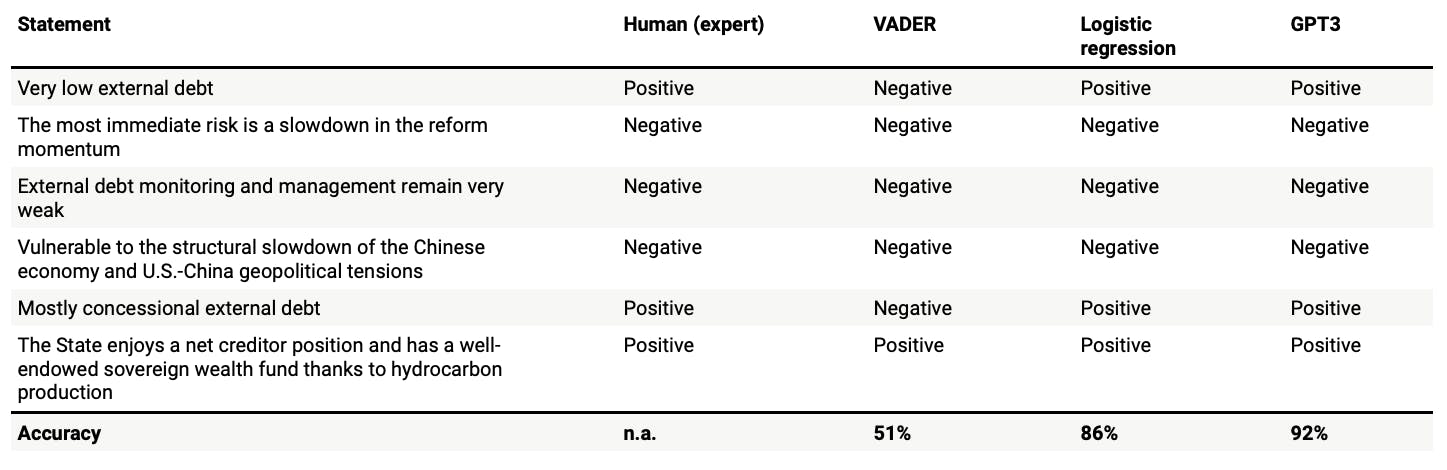
And we have a winner: with an accuracy rate of 92%, GPT-3 is the best tool we tried for automated sentiment analysis of country risk-related text.
This method of sentiment analysis isn’t quite free: the computing power GPT-3 needs to analyse 1,000 tokens (around 750 words) costs between USD 0.0004 and USD 0.02. For the 2,500 sentences we used in blog post, we spent less than a dollar. However, the cost of using GPT-3 at a larger scale by integrating it into our CountryRisk.io Insights platform would be much more significant—perhaps not significant enough to deter us from doing so, but certainly greater than our current, virtually cost-free model.
Outlook
As analysts, we can greatly benefit from understanding the basics of these new algorithms and training them with our hard-earned experience. In short: these tools are only as valuable to the extent that we combine them with deep domain knowledge.
We plan to integrate some of these insights and associated research into an upcoming platform update, and we’re looking forward to seeing how we might use them for economic narrative monitoring. Although we might not use GPT3 for sentiment tracking, we did learn a lot about it and can see a range of other potential applications for this intriguing new tool—more on that in a future blog post.
[1] We have three categories: Positive, Neutral and Negative. We used -0.05 as the threshold for negative and 0.05 for positive when mapping VADER’s categorisation to the human categorisation.